Education
How did you fare in high school mathematics, physical sciences and computing? Which were strengths and which were most enjoyable? How did you rank, competitively, in them?
For mathematics I can say good enough, I can grasp the concept. For physical sciences – we only have chemistry and physics – my grades are not good but not bad either, I think average in my class.
If I can recall, my strengths and most enjoyable subject probably is mathematics. The reason is that our mathematics’ teacher is supportive and can present the subject that is understandable by students. She even provides after school classes for students that need it.
In my class, my rank may be average or below, but for the entire school probably above average. Let me provide a context here. In Indonesia – and probably applied to most South of East Asian schools too – a class is assigned to a room, and each room is assigned 30-35 students that stay in that room until the next grade. In my school, at that time, there was a special class that was different from others, we call it "Kelas Unggul" (Superior Class if translated to English literally). The students in that class are top grades students selected by schools. If the students perform badly at the end of the year, they may be moved to other classes. I stayed in "Kelas Unggul" from the beginning until I graduated from high school.
Which degree and university did you choose, and why?
I chose the degree in computer engineering at Politeknik Negeri Bandung (Bandung State of Polytechnic).
At that time, in my province (West Sumatera, Indonesia), there was no university with Computer Engineer or Information Technology degree yet. In order to get that degree you need to move to the central island, West Java, around 1,407 KM from my hometown. So I did it. After high school, I moved to West Java and tried to get into one of the universities that have a computer science/computer engineering/information technology degree. One of the top universities that provides that degree is Bandung State of Polytechnic.
What did you enjoy most about your time at university?
The last year of university. In my faculty, the last year is where students need to complete and finish the last and final project in a group (one group consists of two or three students) as a prerequisite to graduate. The faculty is open and allows students to stay (sleep) on campus until they finish their final project. So, most of male students, including me, stay on campus during that time. We play, eat, and learn together until we graduate.
Outside of class, what were your interests and where did you spend your time?
Outside of class my interests at that time were playing games, mostly Counter Strike, in the public internet cafe or LAN on campus.
I am also a member of the Linux club on campus, where we usually hang out, share, and learn anything about Linux after class. Besides that, we either play soccer or basketball outside.
What did you achieve at university that you consider exceptional?
Finishing my final project "Voice communication (VOIP) using SCTP".
For most people, I think this is not considered exceptional, but for me personally it is. From knowing nothing about computer programming, until I can write voice communication using a new protocol that is available only on Linux (SCTP), in my opinion, is considered hard. You need to have knowledge on socket programming, audio programming (reading and writing to device drivers using ALSA), thread programming, and GTK library, to be able to pull that up.
Context
Describe your experience designing and building highly distributed, highly concurrent software
My first experience building distributed software is at Proofn.com. We build an application that combines chat and email into one platform. The backend services are developed using Go language. We use HashiCorp’s Consul for service discovery and Vault to manage secrets. For synchronous messaging between services we use gRPC, and for asynchronous messaging we use Nats Streaming (also known as JetStream as of today), both are using Protocol Buffers (Protobuf) as message format.
The overall design is more or less looks like diagram below,
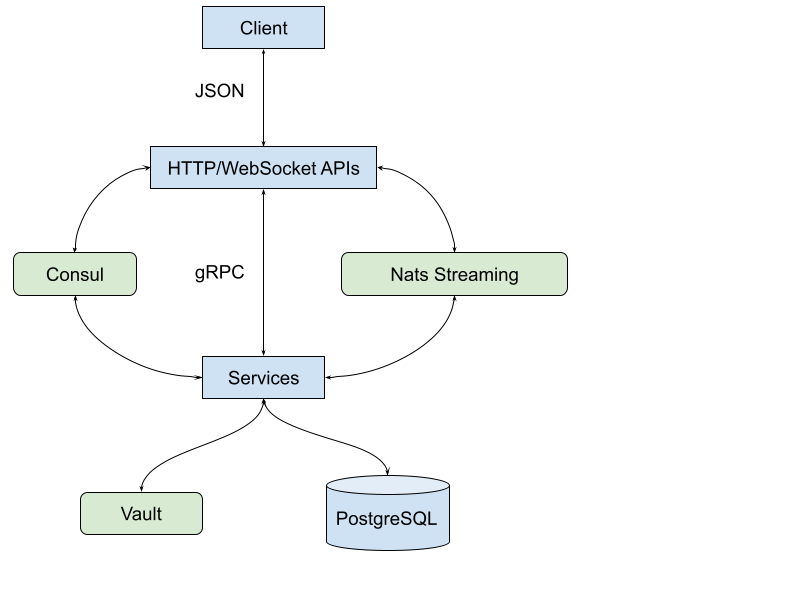
When I review this model again, there are several issues with it, in terms of complexity. The first issue is related to the message format between Client-HTTP/WebSocket and HTTP/WebSocket-Service. We create two different types that represent the same values. One for Client, where we need to convert from/to JSON, and one created by Protocol Buffers to communicate between services. For example, when message X needs to be passed to backend service, we convert X into Protobuf model (Go struct), and when we receive the response back from service we convert back to a model (Go struct) that is convertible to JSON.
The second issue is related to Consul and Vault. Using Consul may make sense if the IP address of service changes in every deployment – at that time we did not have Kubernetes yet – so all services deployed to single, different VMs that have static, internal IP. By knowing where the services are located, initially, we can make it part of the components that are deployed along the services. Related to Vault, there are parts of configuration that can be safely stored in the database and parts of secrets that can be separated into components that are also deployed along with services.
Later, at Tokenomy.com, I took my experiences from Proofn.com to design and build cryptocurrency trading engines. The legacy trading engine is written in PHP and the new one that I build is using Go. In my design, I try to simplify it. I use a message bus model, using Nats as the core messaging bus and queue service. The communication, synchronous and asynchronous, between services are using Nats native protocol and APIs with Gob as a message format. The following diagram show the simplified design of the distributed software,
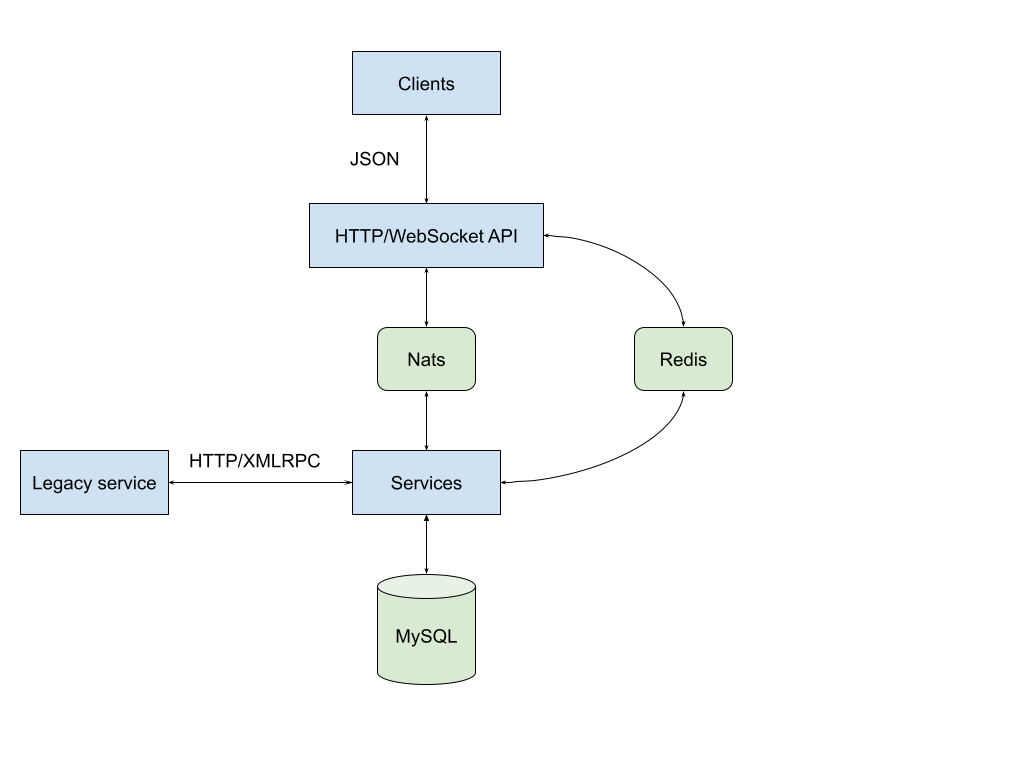
Using the message bus model in distributed services, we drop usage of service discovery. Every service that needs to communicate with other services publish and consume it through known "subjects". Using gob as message format we remove redundant, duplicate types that need to be passed between services. We deploy any configurations that are not critical into the database (could be Redis or MySQL, depending on the type of configurations) with proper grant and access; and any secrets that are critical as components of services. In this way the layer and critical paths are kept minimal.
Give details of your practical experience with Kubernetes, and with container-based operations in general
My experience with Kubernetes is not long, only a couple of months at Tokenomy.com, because the container life cycle affects one of our services.
In the initial iteration of the new trading engine, we use Kubernetes for deployment, in production. Inside the trading engine, there is one service that can be run only as one instance, we called it broker service. This is the service that serves requests for trading, deduct user assets, and open or close the orders based on left over amount. During deployment with Kubernetes, to be able to "Terminate" the previous container, the new container state must be "Running" first. When the new broker service is deployed, there is a time delay where two broker services are in the state "Running". This causes two different requests that affect the same users processed by two different broker services, which cause discrepancy in user assets.
For example, let’s say current user assets is 100, and one transaction deduct user assets by 10 and another by 20. If both are processed by a single broker service, the final user balances should be (100-10)-20=70, but since both brokers are running at the same times, the final balance could be 100-10=90 or 100-20=80, depending on which one writes last to the database.
After we found that issue, we moved back all services to be deployed to VMs, so we can control how each service is being deployed. We may find the solution to these issues while still using Kubernetes, but the time that we lose by trial and error is greater than moving back deployment to VMs. We may not only lose potential users at the time we solve these issues, but also users that can exploit these issues that affect company assets and credibility.
My experience with container-based operations started from 2015, when working at Proofn.com. As the new technology, I need to learn how it works so I experiment by building Docker images from scratch using Arch Linux as base operating system (OS). Once I know how a container works, we use docker images for local development and deployment of applications at Proofn.com.
Have you had any involvement in the Cloud Native community, or contributed to any related projects?
No, not yet.
Outline your thoughts on the challenges of operating a well integrated and robust data platform
I assume in this context the data platform ingest and serve queries from and to clients. Below, I provide several challenges that I can think of when operating a well integrated and robust data platform.
On the ingestion side, the biggest challenge is to keep the service that consumes the data alive 24/7. If the service that consumes the data goes down, some information may be missing and this may cause discrepancies or probably inconsistent on the client side when queried back. Some solutions can be implemented, for example 1) providing high availability by running multiple services at separated locations; 2) providing a fallback where incoming data is stored temporarily when the service is down; 3) implementing an API with a retry scenario, if the client pushes the data and it fails to be stored properly, client should be informed accordingly and retry it again later.
On the query side, one of the biggest challenges is to provide a quick response to clients. Choosing the right storage, database, and the structure to store the database is another challenge on its own.
Engineering Experience
What kinds of software projects have you worked on before? Which operating systems, development environments, languages, databases?
At Tokenomy.com we build a platform based on cryptocurrencies. There are several features that we build, the following projects are the one that I take lead and responsibilities on,
-
Trading engine, rewrite and implement new trading engine, where users can open and trades their assets in real time
-
Loan, a module where users can exchange their assets with others’ assets on limited timelines.
-
Authentication, unify and rewrite the HTTP APIs for public and internal authentication
We use a variety of GNU/Linux distributions including Ubuntu, Debian, CentOS, and Arch Linux. For development environments, we use VM with VirtualBox or Qemu for running and testing our application, some parts of it are connected to Google Cloud Platform (GCP). In staging and production we use GCP. For development languages and tools we use Go, PHP, Java, Nats, Redis, golangci-lint, git, and make. For the databases we use MySQL and PostgreSQL.
At Proofn.com we build messaging platforms that combine chat and email into one application, web and mobile. We use GNU/Linux as the main OS, mostly CentOS and Amazon Linux. For development environments, in the local environment we use Docker and VirtualBox; in staging and production environments we use Amazon Web Services (AWS). For development languages and tools we use Go, JavaScript, TypeScript, Nats, Consul, Vault, git, and make. For the database we use PostgreSQL.
Below is a list of projects that I have worked on as a consultant and/or as an employee at a software company.
-
Sistem Informasi Manajemen Aset Negara (SIMAN) - Web application for managing assets in all divisions of the Ministry of Finance.
-
Operating System: Windows Server
-
Programming language: Java
-
Development environments: Apache Tomcat, ExtJS, and git
-
Database: Oracle
-
-
Sistem Informasi Kekayaan Negara Dipisahkan - Early Warning System (KND - EWS) - System information that collects and aggregates data from SIMAN.
-
Operating System: Windows Server
-
Programming language: Java
-
Development environments: Apache Tomcat, ExtJS, and git
-
Database: Oracle
-
-
E-Arsip - Web application for digital archive management system
-
Operating System: Windows Server
-
Programming language: Java
-
Development environments: Apache Tomcat, ExtJS, and git
-
Database: PostgreSQL
-
-
Sistem Informasi K3PL (SI-K3PL) - Web application for system, management, data processing and reporting of K3PL (occupational health and safety and waste management) at National Gas Company
-
Operating System: Windows Server
-
Programming language: Java
-
Development environments: Apache Tomcat, ExtJS, and git
-
Database: Microsoft SQL Server
-
-
JejaGPS – Research and develop server application (web) and client application (Windows service) for tracking Panasonic Toughbook notebook through GPS
-
Operating System: Windows
-
Programming language: Python
-
Development environments: lighttpd, ExtJS, and git
-
Database: PostgreSQL
-
-
Paket Aplikasi Sekolah SMU Web (PAS-SMU Web) - Web application for system information in SMU (senior high school), used by all public schools in Indonesia.
-
Programming language: PHP
-
Development environments: Apache, ExtJS, and git
-
Database: MySQL
-
-
(Research) Database Replication for Oracle - Research and develop software for replicating Oracle Database in near real-time.
-
Operating System: Sun OS, GNU/Linux
-
Programming language: C
-
Development environments: libvos, Shell script
-
Database: Oracle
-
-
SMS Gateway - Build and maintain an SMS gateway application.
-
Operating System: GNU/Linux
-
Programming language: PHP
-
Development environments: Kannel, Shell script
-
-
TDP, Wholesale and IRB (PT. TELKOM) - Develop ETL software for processing SMS and call transactions, in text file, and daemon for managing workers and pipelines
-
Operating System: GNU/Linux
-
Programming language: C
-
Development environments: make, git
-
Database: Oracle
-
-
Paket Aplikasi Sekolah SMU (for Ministry of Education Republic Indonesia) - System information for senior high school, used across all public schools in Indonesia.
-
Operating System: Windows
-
Programming language: Power Builder
-
Development environments: Install Shield, git
-
Database: MySQL
-
-
Paket Aplikasi Sekolah SMP (for Ministry of Education Republic Indonesia) - System information for junior school, used across all public schools in Indonesia.
-
Operating System: Windows
-
Programming language: Power Builder
-
Development environments: Install Shield, git
-
Database: MySQL
-
-
Sistem Informasi Pendidikan Nasional (for Ministry of Education Republic Indonesia).
-
Operating System: Windows
-
Programming language: Power Builder
-
Development environments: Install Shield, git
-
Database: MySQL
-
-
Sistem Informasi Penerimaan dan Pemantauan PBB (Regional Government of Bandung City) - System information for property tax income
-
Operating System: Windows
-
Programming language: Power Builder
-
Development environments: Install Shield, git
-
Database: Oracle 8i
-
Give details of your Python software development experience to date, how would you rate your competency with Python?
My only professional experience with Python only one time, when working on an application that tracks Panasonic Toughbook notebook through GPS. The software consists of server and client. The server provides an API where clients submit the GPS data and store it into a database, and web interface to view the client position using Google Maps. The client is a Windows service that fetches GPS data periodically and sends it to the server.
I want to keep learning and using Python, unfortunately most of my professional work is dealing with governments, and one of their requirements is using Java as a programming language.
I would rate my competency with Python as a beginner.
Give details of your Go software development experience to date, how would you rate your competency with Go?
When I first heard Go, around 2015, I decided to use it to write my thesis "Detecting Vandalism on English Wikipedia Using LNSMOTE Resampling and Cascaded Random Forest Classifier", a combination of machine learning and big data. In the same year, my company Proofn.com, also began rewriting the backend services from JavaScript to Go.
Later, around 2018, I begin to rewrite my open source project, DNS resolver, from C to Go, create a shared libraries that are specially written for Go as bedrock for my future Go projects. Using Go, I have implemented DNS server and client from scratch, WebSocket server and client from scratch, custom HTTP library that extend standard package, library for creating workers and managers on top of HTTP, library for testing HTTP and/or WebSocket endpoints, configuration management software, and static web server generator using the Asciidoc markup.
In 2019, after Proofn.com ran out of funds, I joined Tokenomy.com to start rewriting their trading engine from PHP to Go, laying the foundation for their API v2.
Given a level competency: master, expert, advanced; where master is the one who writes the Go compiler, and an expert who knows and uses all features of Go language in and out; I would say my competency is in between expert and advanced. There are parts of Go language that I have not fully explored and applied yet in my day to day work, for example fuzzing.
Which project or piece of software are you most proud of, and why?
Professionally, I would say the trading engine at Tokenomy.com. The previous trading engine was written in PHP. I write the new one by reading the PHP code line by line. In order to make the new trading engine work consistently with the previous one, we rigorously apply the Test-Driven Development (TDD) on new code and create integration tests to check the output between previous engine and new engine. There are many things that I learned from writing this piece of software, some of them including floating decimal gotcha, caching and database transactions for multiple orders, and building distributed services using Nats with a message bus model.
Personally, the DNS resolver, rescached. I learn to write the DNS protocol from zero by reading the RFCs. This is one of the software outside of my professional work that is not related to Create, Read, Update, Delete (CRUD) – web applications. The original goal of rescached is to provide ads blocking in my local environments and to bypass DNS blocking (hijacking) from my ISP. Now, it is used as an internal DNS that provides custom zones and caching for small to medium user bases. I used it in my previous two companies as a DNS server for our VPN networks.
Give details of any experience you have with automated provisioning
tools, configuration management and infrastructure-as-code tools
At Proofn.com, I use Ansible to provision our infrastructure and to set up and configure applications for all environments; including local, staging, and production.
At that time, our Ansible scripts grew beyond its capability. There are several issues that I think can be improved in Ansible, so we created a wrapper that can help us simplify some tasks. Below, I will try to describe some of those issues that I can remember.
First, using YAML as a task definition is not intuitive. A simple task like copying a file requires writing multiple lines. Second, there is no option to execute specific tasks inside the role. This cause us adding variable "step" to every line in task so operator can execute the role start from specific "step",
- name: Copy config when: step | int <= 2 template: src: scan.conf dest: /etc/clamd.d/scan.conf - name: Start and enable the service when: step | int <= 3 service: name: clamd@scan state: restarted enabled: yes
Third, structuring the playbook and roles becomes the "art" of itself. If I show our Ansible repository to someone who already knows Ansible, they may be wondering where to start or needs time to learn.
Using that experiences I write awwan, my own provisioning and configuration management tool using UNIX like approach. Awwan script is like shell script, so anyone who knows shell script should be able to read and write awwan script naturally. Awwan does not have a module to "talk" to cloud providers or remote servers, instead users must combine it with the official or system CLI tools, for example, "aws" CLI for AWS or "gcloud" CLI for GCP, scp, or rsync.
Here is the awwan script to provisioning new VM in GCP using gcloud,
#require: gcloud config configurations activate {{.Val "gcloud::config"}}
gcloud compute instances create {{.Val "host::name"}} \
--zone={{.Val "gcloud::zone"}} \
--image-project=debian-cloud \
--image-family=debian-11 \
--labels=owner=company-name \
--subnet=default \
--machine-type=n1-highmem-2 \
--metadata=block-project-ssh-keys=TRUE
Looks like a shell script but the host name and zone are dynamic based on values in awwan environment variables. Also, if we convert the above example of Ansible script to awwan it would be like this,
#put! {{.ScriptDir}}/scan.conf /etc/clamd.d/scan.conf
sudo systemctl enable clamd@scan
sudo systemctl start clamd@scan
How comprehensive is your knowledge of Linux, from the kernel up? How familiar are you with low-level system architecture, runtimes, packaging and command line tooling?
From the kernel side, I have experienced compiling my own kernel. Now, I only need to know which modules need to be included in initramfs, and which system variables need to be set using sysctl.
From low-level system architecture, I used to know how the system works from boot up, to boot loader, to init, until starting the tty (shell). Now, since the introduction of UEFI and systemd, I only know the surface.
From the runtimes side, I have experience with Valgrind/Callgrind for detecting memory leaks and tracing the calls for debugging, I have used {LD|C}FLAGS to compile and/or run custom code/binary.
From the packaging side, I can not recall if I have written the RPM package for OpenSuSE. The history is lost due to OpenSuSE changing their wiki and forum, and I cannot find one right now. Now, since I use Arch Linux, I have create several Arch User Repository (AUR) packages that I needed.
From the command line tooling, I can say that I am very familiar with it.
Describe your experience with public cloud based operations - how well do you understand large-scale public cloud estate management and developer experience?
My experience with public cloud based operations started around 2015 with Amazon Web Services (AWS) when working at Proofn.com. My role at that time was as DevOps engineer, building the infrastructure from zero for all environments. Later at Proofn.com, the company put a trust in me to help manage the infrastructure in Google Cloud Platform (GCP) consisting of more than 70 VMs and databases in staging and production environments.
Regarding the public cloud management, or infrastructure in general, there are three components that I always applied: security, logging, and monitoring. An example of security practices are by accessing the resources only from VPN (I setup OpenVPN when working at Proofn.com, and then WireGuard at Tokenomy.com), apply firewall to all VMs – limit public access to only allow on specific ports, rotate or renew the authenticate keys (SSH, VPN, passwords) periodically, use internal IP for access between internal resources in the same subnet, and log access to each resources for future audit. An example of logging practice is by collecting and centralising the system and application logs into one central dashboard where everyone can see and review the system when needed. An example of monitoring practice is by collecting the system and application resources metrics (in example, CPU and memory usage, application memory), with alerts that notify us when a certain threshold or filter are reached or triggered by system or application.
Related to developer experiences, I have experienced setting up continuous integration, a pipeline, that allows the code to be built, tested, and deployed on each single push to git repositories, based on the branch where the code pushed. The tools that I used are Buildbot and Jenkins. Once the application is deployed to the cloud, we provide the developers access to a log and monitoring dashboards where they can review the running application.
Outline your thoughts on quality in software development. What practices are most effective to drive improvements in quality?
In my opinion there are two practices that can improve the quality of software: testing and working as a team. Everyone is testing. From the developer side, they should apply the Test-Driven Development (TDD) model, this is to minimise breaking changes, unexpected bugs, and give developer confidence, when we need to make any changes to the code in the future (refactoring). From the product side, periodically discussing, showing, and testing the application together with team members also allows us to cross check the behaviour that we implement is correct, according to design, or requirements.
Working as a team means we are not in silo when developing software, there should be other team members, for example other developers, designers, QA engineer, or product; that help each other to guard, realign, correct, suggest, or remind us when needed. Pair programming with other developers also helps a lot to improve quality in the development side.
Outline your thoughts on documentation in software projects. What practices should teams follow? What are great examples of open source docs?
In software projects there are two documentations, public and internal. The best practices for public documentation – it could be public for team only or public for users – should be written with the help of all team members, so everyone in the team has the same understanding of the software that we build.
The internal documentation is the documentation related to the source code. The best practice is to put it as close as possible with the source code, either as comments inside code or part of the repository where the code belongs. This documentation should be accessible (readable and writable) when developers read or change the code.
An example of great open source documentations are glibc, systemd manual pages, git SCM, and PostgreSQL. Some criteria of great documentation are comprehensive, easy to read and navigate, and provide examples.